paired t test
Wikipedia says:
“….
Paired samples t-tests typically consist of a sample of matched pairs of similar units, or one group of units that has been tested twice (a “repeated measures” t-test).
A typical example of the repeated measures t-test would be where subjects are tested prior to a treatment, say for high blood pressure, and the same subjects are tested again after treatment with a blood-pressure lowering medication. By comparing the same patient’s numbers before and after treatment, we are effectively using each patient as their own control.
…”
http://en.wikipedia.org/wiki/Student%27s_t-test#Paired_samples
http://www.stats.gla.ac.uk/glossary/?q=node/355
http://www.gla.ac.uk/sums/users/jdbmcdonald/PrePost_TTest/pairedt1.html
One sample t test
The one sample t test is used to test sample data against the Null Hypothesis (H0). In this case the Null Hypothesis is whether the sample mean matches the population mean.
chi square test statistic
The Chi square compares the observed data with the Null Hypothesis.
Chi square test looks at single set of data and Null Hypothesis.
- Ho The no difference or no association hypothesis that shows no difference between observed and expected data.
- H1 This postulates that there is a difference between observed and experimental data.
Expected = row X col total / grand total
χ2 = sum ((observed – expected) /Expected)2
χ2 and DF/degree of freedom gives the test statistic
A big difference between observed and expected results in a large test statistic (χ2) and so leads to a rejection of the Null Hypothesis (Ho)
The greater the value of the test statistic, the greater the evidence against the Null hypothesis -leads to a smaller p -value
“…The p-value is the area under the chi-square probability density function (pdf) curve to the right of the specified χ2 value…” http://www.di-mgt.com.au/chisquare-calculator.h
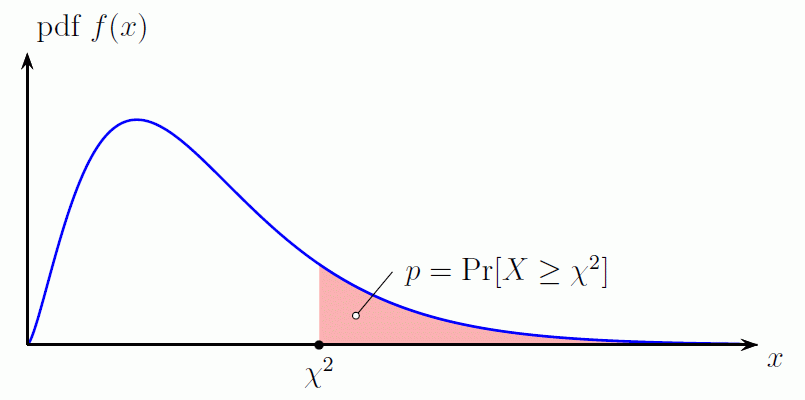
Source: di mgt.com.au
p value is the area to the right of the test statistic. The less the number (< 0.05) the more likely to reject the Null Hypothesis
http://www.stat.ucla.edu/~kcli/stat13/stat13-lecture14.pdf
Nice video explaining it all.
Cat Now Found in Hollingdean and Hollingbury
Missing. Found!
A neighbour at the end of the road spotted one of our notices and she’s back home. Skinny but looks OK.
Twitter Bootstrap and WordPress
This is my first attempt to mix twitter bootstrap and WordPress. I need to try harder. I’m using a version of Rachel Baker’s WordPress Theme based on Twitter Bootstrap. I can’t claim credit so that’s where I got it from.